Hatthini
Conversational Companion for Emotional Regulation
Overview
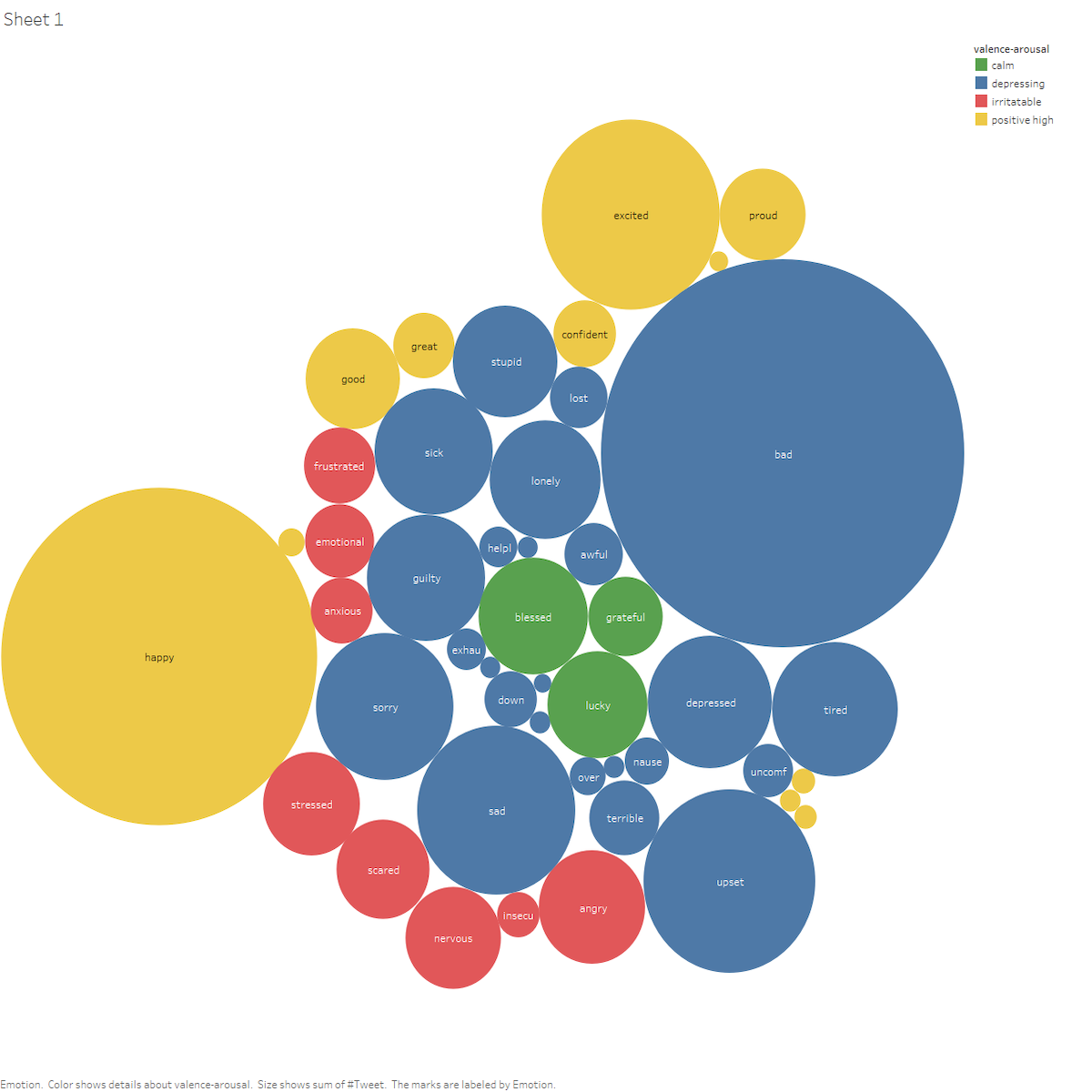
We designed a large scale dataset on Emotion and Emotion-cause to enhance the performance of exisitng Emotionally Aware Dialogue Systems.
Role
- Assisted in designing a comprehensive pipeline for data gathering, cleaning, labeling, and validation, resulting in a rich dataset of 700,000 emotion-cause tweets from an initial 1M dataset.
- Implemented key preprocessing techniques:
- Text normalization, tokenization, topic modeling, and semantic analysis to enhance dataset quality.
- Incorporated human validation via Amazon Mechanical Turk for accuracy assessment.
- Labeling the dataset with state-of-the-art LLMs like GPT-3.5, BART, and T5.
- Fine-tuned and evaluated the state-of-the-art LLMs like GPT-3.5, BART, and T5 with the enhanced dataset for optimal performance.
- Developed a mobile interface to interact with the emotional regulation companion.
Findings
- 90% of emotion-cause labels in the dataset have an average rating of 4.0 or above across relevance, fluency, and consistency as reported by annotators.
- Achieved optimal performance across tasks, demonstrating the dataset's value in advancing emotion-cause analysis.